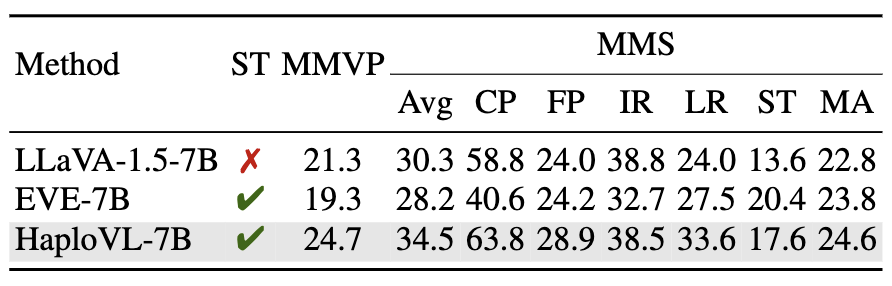
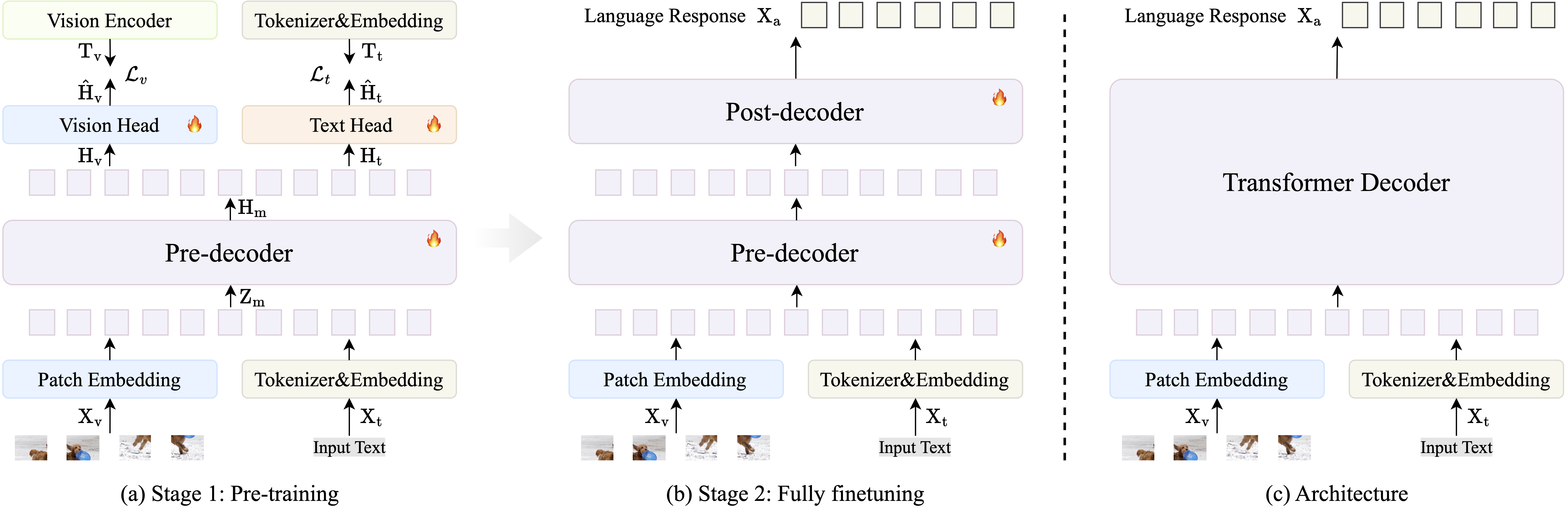
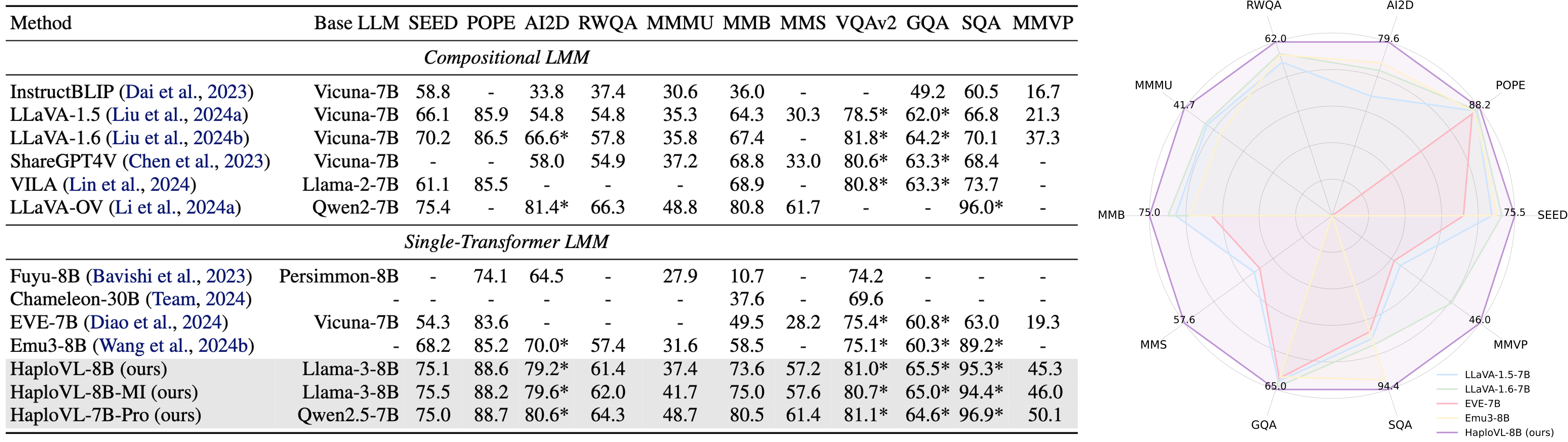
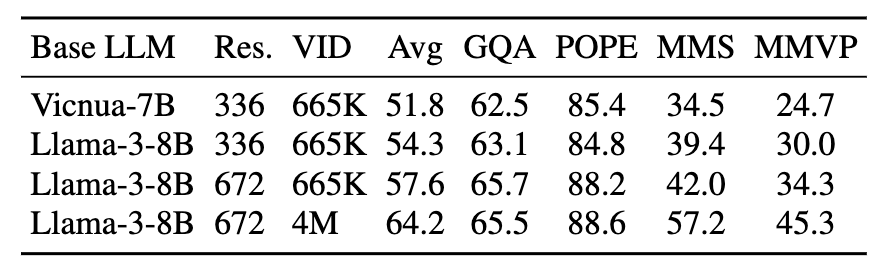
- 🌟 A more advanced language model delivers significantly superior results.
- 🌟 Higher input resolution enhances performance, as the LMM can capture finer-grained visual details.
- 🌟 Expanding the visual instruction tuning data leads to substantial improvements by enriching the LMM's knowledge.